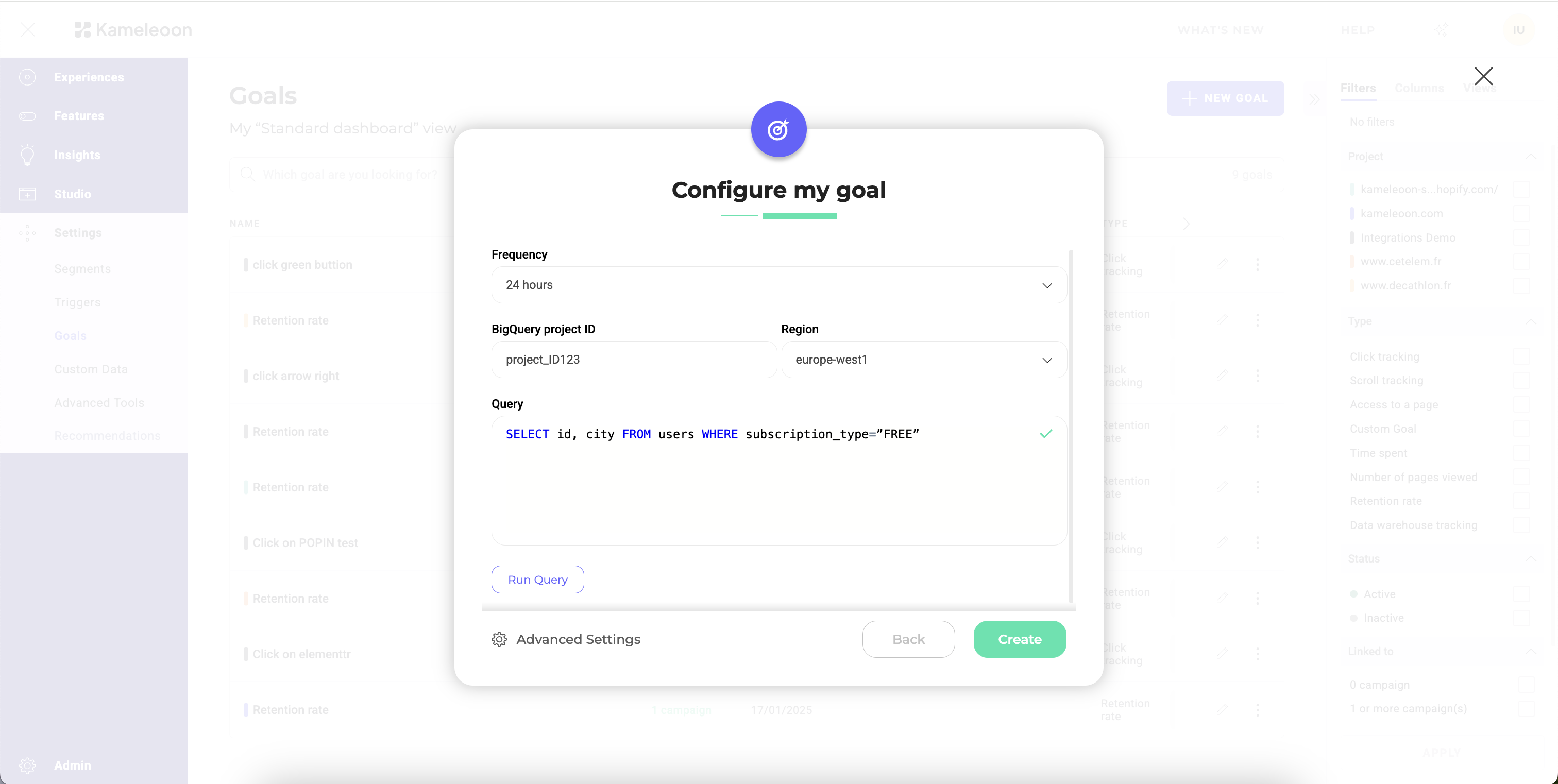
- Settings > Goals > New goal をクリックします。
- 次の情報を入力します:
- Name: ゴールにわかりやすい名前を付けます。
- Type: Data Warehouse Tracking を選択します。
- Data warehouse: Databricks を選択します。
- Project: 目的のプロジェクトを選択します。Databricks が有効化されているプロジェクトのみが一覧表示されます。
- Next をクリックします。
- 次のウィンドウで、追加の詳細を入力します:
- Frequency: タスクを実行する頻度を選択します。
- Databricks catalog: Kameleoon が読み取るスキーマを含む Databricks カタログの名前を入力します。
- Query: 2 つの列を持つ SQL クエリを入力します。最初の列にはユーザー ID(または
kameleoonVisitorCode)、2 番目の列にはそのユーザーの追加情報(エンリッチメント)として追加する値が含まれている必要があります。
- Validate をクリックしてゴール設定を保存します。
データウェアハウスの保持期間: イベントがポーリングされるためには、Kameleoon は、イベントが発生してから少なくとも 72 時間、入力クエリでアクセス可能であることを要求します。
クエリ形式
クエリは特定の形式に従う必要があります:visitor_id は訪問者の一意の ID を表す列で、conversion_timestamp はコンバージョンが発生した正確な時刻を表す列です。Databricks では、conversion_timestamp 列は Timestamp 型の列である必要があります。
各コンバージョンに収益を関連付けたい場合、クエリは代替形式に従う必要があります:
revenue は各コンバージョンの収益を含む列です。
より複雑なクエリの場合、次のようにサブクエリを作成することでこの形式に従うことができます:
WITH 句が追加されて、Databricks ウェアハウスで毎時実行されます。コンバージョンは毎時収集されますが、実験結果にマージされるのは 1 日に 1 回のみであることに注意してください。
インジェスチョン前にクエリを実行する
インジェスチョンタスクを保存する前に、Kameleoon で直接クエリをテストできます。テストにより以下が可能になります:- リアルタイムで接続を確認する。
- 認証情報とアクセス権が正しいことを確認し、最初のデータインポートを待たずに問題を即座に検出できるようにする。
- データの構造とアクセス可能性を検証する。