データウェアハウス統合は、当社の Web Experimentation および Feature Experimentation モジュールのプレミアムアドオンとして利用できます。詳細については、カスタマーサクセスマネージャーにお問い合わせください。
- 特定のデータドリブンなゴールの定義と定期的な更新を可能にし、意思決定プロセスを簡素化し、キャンペーンが目標と整合することを保証します。
- BigQuery メトリクスを主要業績評価指標 (KPI) として活用し、キャンペーンパフォーマンスの包括的なビューを提供します。
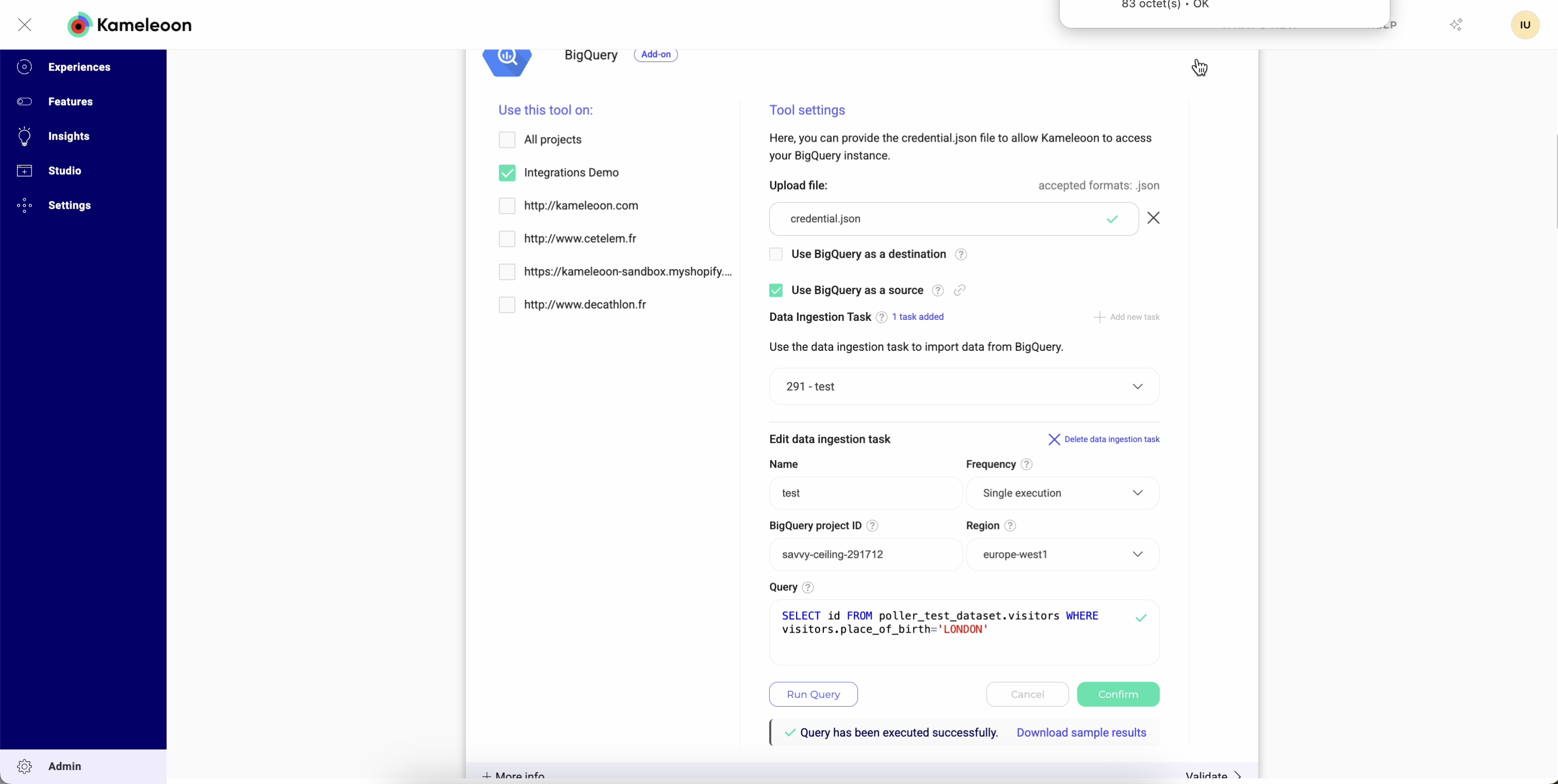
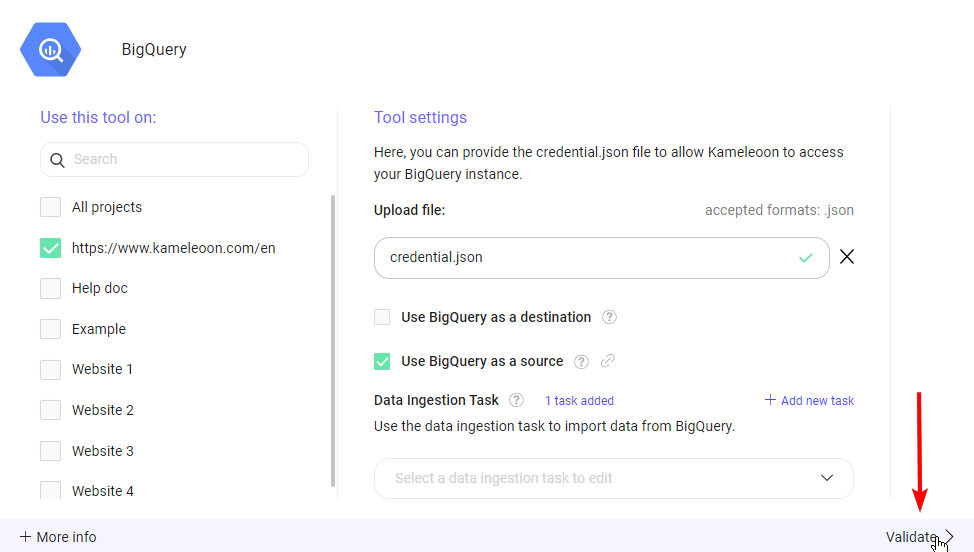
- 機能を有効化: 選択したプロジェクトの構成で、Use BigQuery as a source と表示されたチェックボックスをオンにして機能を有効化します。
- データ取り込みタスクを作成: 機能を有効化すると、データ取り込みタスクの作成を開始できます。これらのタスクは、定義された SQL クエリと頻度に基づいて BigQuery から特定のデータを定期的に取得します。新しいデータ取り込みタスクを作成するには、Add new task をクリックします。
- Validate: データ取り込みタスクに必要な情報を提供した後、Confirm をクリックしてタスクを作成します。タスクの命名、SQL クエリの定義、頻度の設定の手順を繰り返すことで、追加のタスクを作成できます。タスクの構成が完了したら、Validate をクリックして構成設定を保存し適用します。
- カスタムデータを作成: データ取り込みタスクを作成したので、Kameleoon のサーバーが、構成した頻度で BigQuery インスタンスでクエリを実行することによってデータの収集を開始します。収集したデータを使用するには、カスタムデータを作成する必要があります。
- セグメントを作成: 収集したデータに基づいてユーザーをターゲティングするための最後のステップは、作成したカスタムデータに基づいてセグメントを作成することです。
データ取り込みタスク
データ取り込みタスクは、Kameleoon 内の BigQuery 統合の重要なコンポーネントです。これらのタスクにより、事前定義された SQL クエリと頻度に基づいて Google BigQuery から特定のデータを定期的に取得できます。データ取り込みタスクを通じて収集されたデータは、Kameleoon キャンペーン内のターゲティング条件として利用でき、高度にパーソナライズされたデータドリブンなユーザー体験を可能にします。データ取り込みタスクの作成
データ取り込みタスクを作成するには: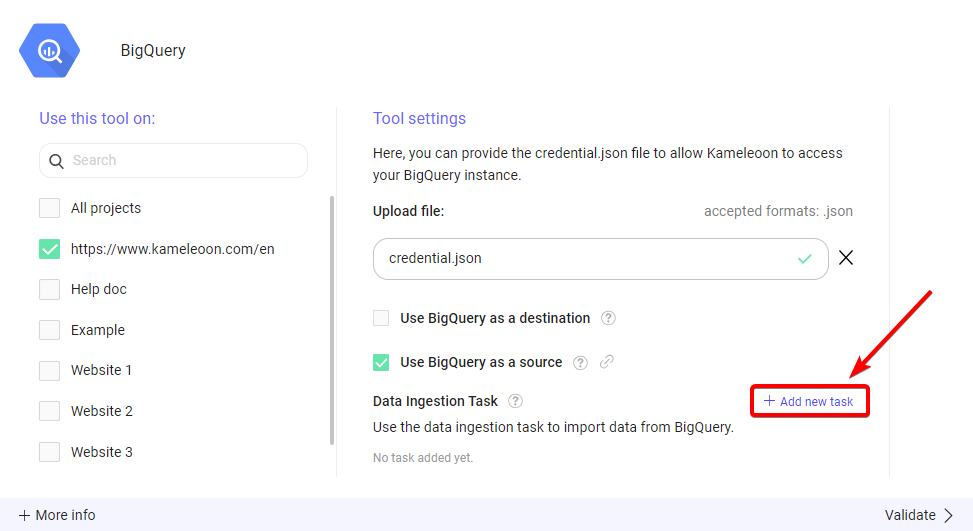
- Add new task をクリックします。
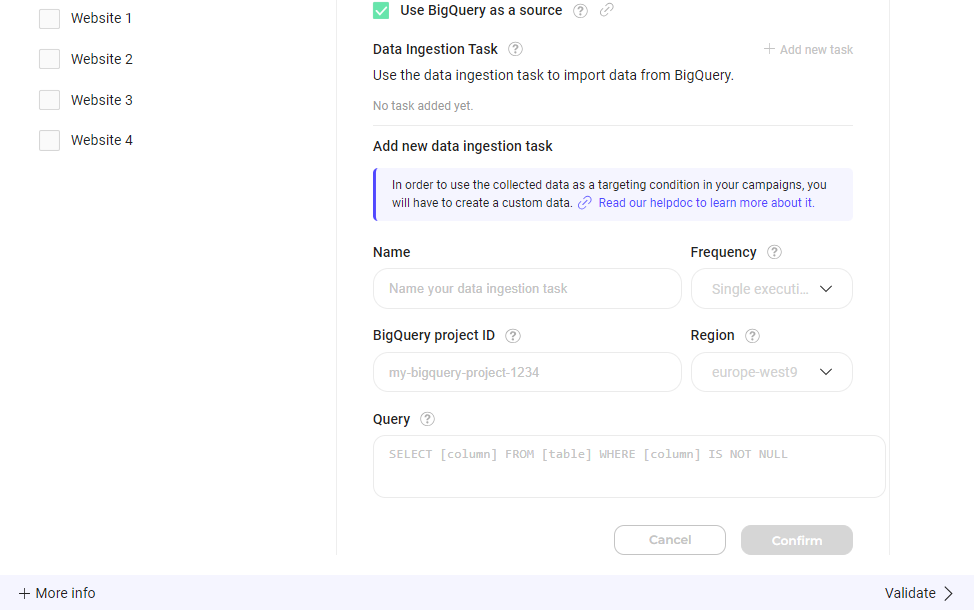
- フォームに入力します:
- Name (必須): タスクに固有でわかりやすい名前を付けて、その目的を識別します。
- BigQuery project ID (必須): Google BigQuery プロジェクトに関連付けられたプロジェクト ID を提供し、データが正しい場所に送信されるようにします。
- Region (必須): 提供されたリストから適切なリージョンを選択します。リージョンの選択により、BigQuery オペレーションの地理的な場所が指定されます (利用可能なリージョン)。
- Query (必須): BigQuery データベースからオーディエンスを取得する SQL クエリを提供します。クエリは以下の特定の形式に従う必要があります:
SELECT visitor_id, attribute_1, .. attribute_N FROM your_events_table
attribute_フィールド: オプションで、高度なターゲティングシナリオに使用できます。これらの高度なユースケースの詳細はこちらをご覧ください。visitor_id: この列は訪問者の一意の識別子を表します。
ガイドライン
列の命名
列名には文字 (大文字または小文字)、数字、アンダースコア (_) のみを使用できます。数字で始めることはできません。
列の順序
統合が正しく機能するためには、列は指定された順序 (visitor_id の後にオプションの属性) で正確に表示される必要があります。
必要な情報をすべて提供したら、Confirm をクリックしてデータ取り込みタスクを作成します。
データ取り込みタスクの更新
データ取り込みタスクを更新するには: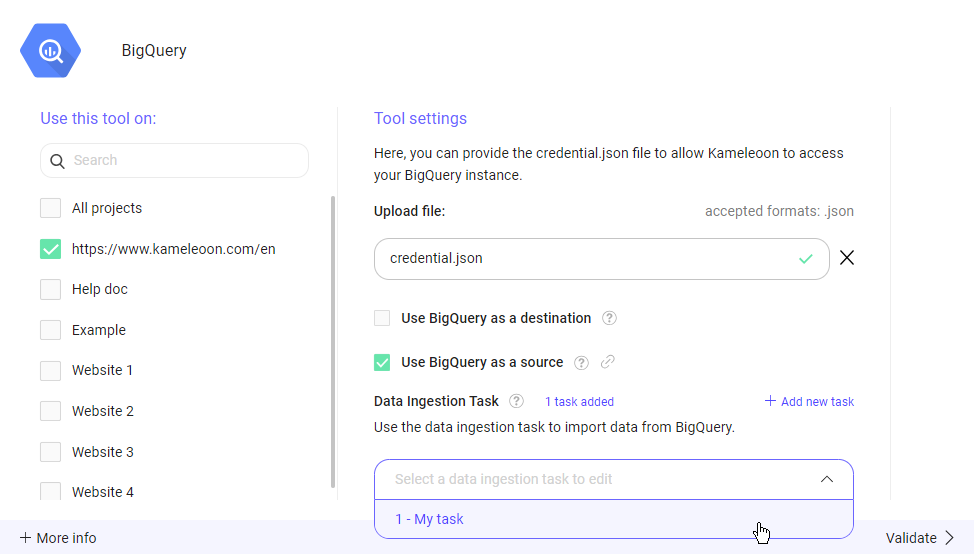
- タスクの選択: まず、ドロップダウンメニューから編集したい特定のデータ取り込みタスクを選択します。
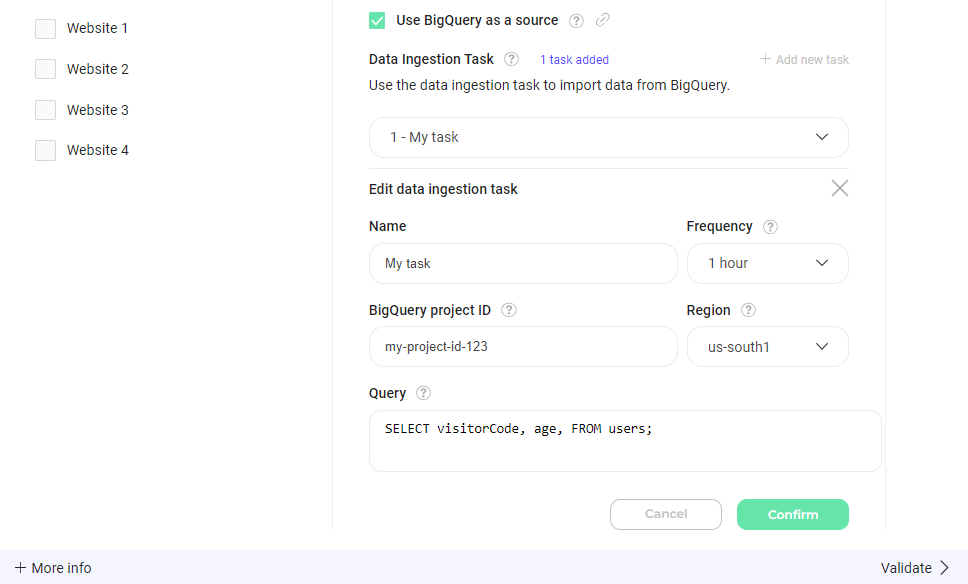
- タスクの詳細を編集: タスクの名前、頻度、BigQuery プロジェクト ID、リージョン、クエリなど、更新したいフィールドを変更します。
- 変更を確定: 必要な更新を行った後、「Confirm」をクリックしてデータ取り込みタスクの変更を保存します。
データ取り込みタスクの削除
データ取り込みタスクを削除するには: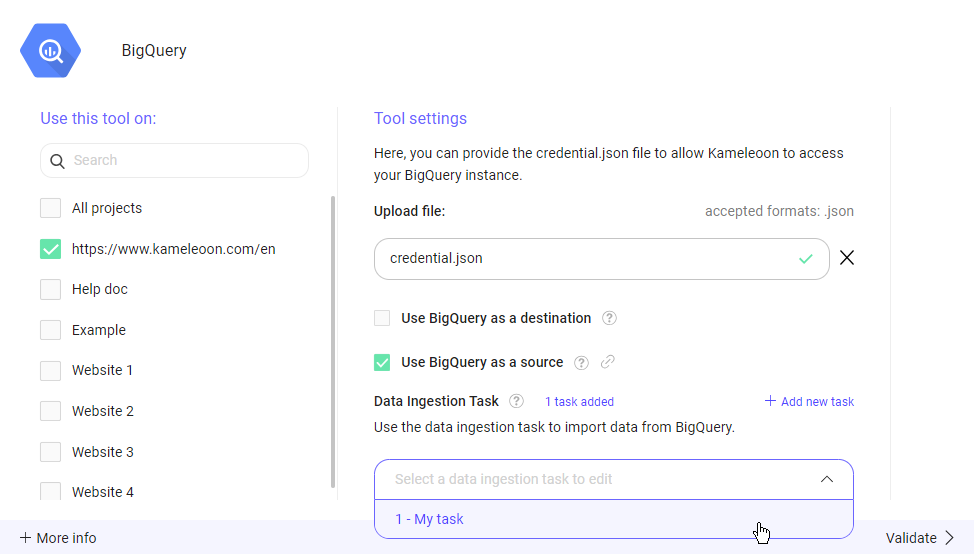
- タスクの選択: ドロップダウンメニューから削除したいデータ取り込みタスクを選択します。
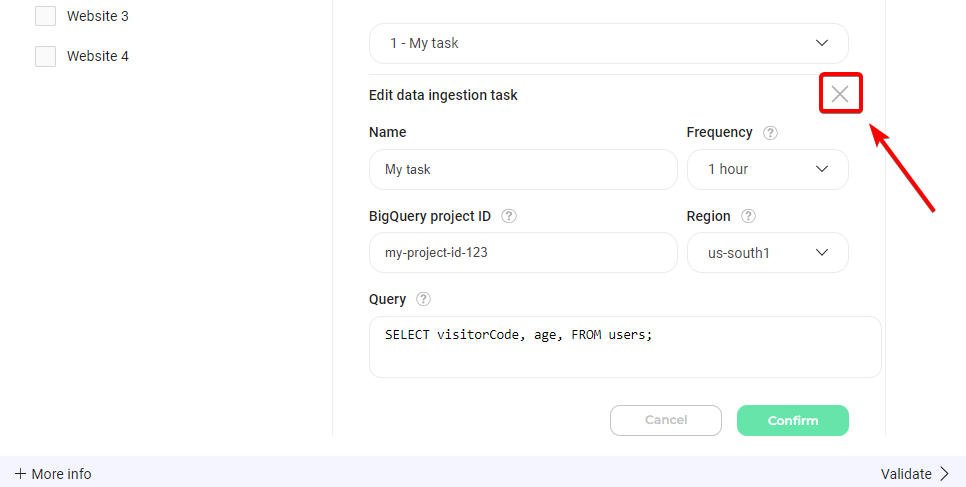
- 削除を開始: Edit フォームの右上にある削除アイコンをクリックします。
- 削除を確定: 確認プロンプトが表示されます。Confirm をクリックして選択したデータ取り込みタスクを削除します。
取り込み前にクエリを実行する
取り込みタスクを保存する前に、Kameleoon でクエリを直接テストできます。テストにより以下が可能になります:- 接続をリアルタイムで確認できます。
- 認証情報とアクセス権が正しいことを確認できます。これにより、最初のデータインポートを待つことなく、問題を即座に検出するのに役立ちます。
- データの構造とアクセシビリティを検証できます。