

- Permet une collecte de données précise, améliorant le ciblage d’audience pour des campagnes personnalisées afin de répondre aux besoins et préférences spécifiques de l’audience.
- Configurez des Data Ingestion Tasks pour extraire efficacement les données de Redshift.
Les intégrations data warehouse sont disponibles en tant que module complémentaire premium pour nos modules Web Experimentation et Feature Experimentation. Pour plus d’informations, veuillez contacter votre Customer Success Manager.
- Activer la fonctionnalité : Dans la configuration du projet sélectionné, cochez la case Use Amazon Redshift as a source.
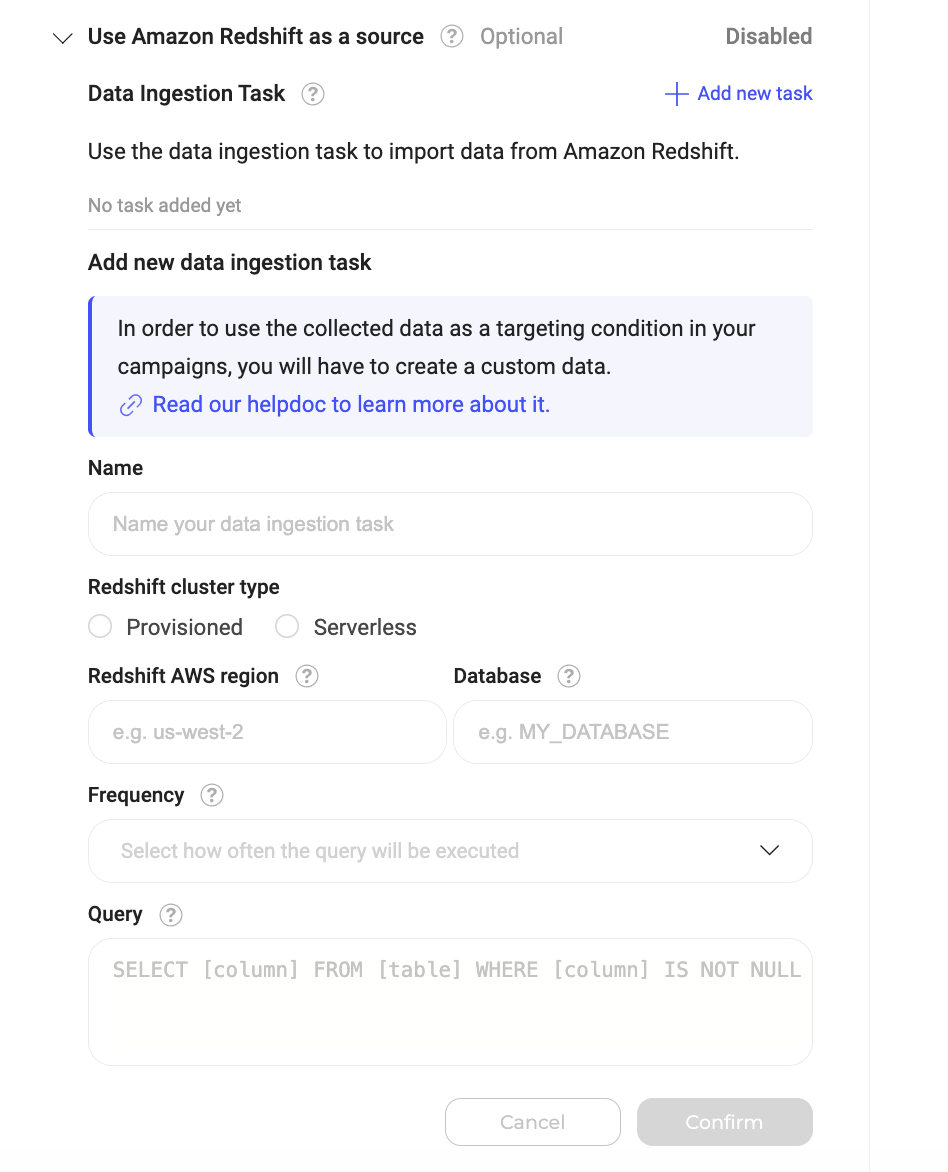
- Créer des Data Ingestion Tasks : Avec la fonctionnalité activée, vous pouvez créer des Data Ingestion Tasks. Ces tâches récupèrent régulièrement des données spécifiques d’Amazon Redshift en fonction de vos requêtes SQL et de fréquences définies. Pour créer une nouvelle Data Ingestion Task, cliquez sur Add new task.
- Valider : Après avoir fourni les informations requises pour la Data Ingestion Task, cliquez sur Confirm pour créer la tâche. Vous pouvez créer des tâches supplémentaires en répétant les étapes consistant à nommer la tâche, définir la requête SQL et définir la fréquence. Une fois vos tâches configurées, cliquez sur Validate pour enregistrer et appliquer vos paramètres de configuration.
- Créer une custom data : Maintenant que vous avez créé votre Data Ingestion Task, nos serveurs commenceront à collecter des données en fonction de la fréquence que vous avez configurée en exécutant la requête sur votre instance Amazon Redshift. Pour commencer à utiliser les données collectées, vous devez créer une custom data.
- Créer un segment : La dernière étape pour cibler les utilisateurs sur la base des données collectées consiste à créer un segment basé sur votre custom data.
Data Ingestion Tasks
Les Data Ingestion Tasks sont des composants essentiels de l’intégration Amazon Redshift dans Kameleoon. Les données collectées par les Data Ingestion Tasks peuvent être utilisées comme conditions de ciblage dans vos campagnes Kameleoon.Créer une Data Ingestion Task
Pour créer une Data Ingestion Task :- Cliquez sur Add new task.
- Remplissez le formulaire :
- Name (Required) : Donnez à votre tâche un nom unique et descriptif pour identifier son objectif.
- Redshift cluster type (Required) : Indiquez si votre cluster Redshift est provisioned ou serverless. Si vous choisissez « provisioned », il vous sera demandé de fournir votre identifiant de cluster. Si vous choisissez « serverless », il vous sera demandé de fournir le namespace et le workgroup de votre cluster.
- Redshift AWS region (Required) : Le code de région de votre cluster Redshift. Vous pouvez le trouver dans votre console AWS. Exemple :
us-west-2. - Database (Required) : Nom de la base de données Redshift contenant les données que vous ingérez.
- Frequency (Required) : Indiquez à quelle fréquence vous souhaitez que la tâche s’exécute et récupère les données de BigQuery (par exemple, par jour).
- Query (Required) : Fournissez la requête SQL qui récupère l’audience depuis votre base de données Amazon Redshift. La requête doit suivre ce format spécifique :
SELECT visitor_id, attribute_1, .. attribute_N FROM your_events_table. - Champs
attribute_: Ils sont optionnels et peuvent être utilisés pour des scénarios de ciblage avancés. En savoir plus sur ces cas d’utilisation avancés ici. visitor_id: Cette colonne représente l’identifiant unique de vos visiteurs.
Les noms de colonnes ne peuvent contenir que des lettres, des chiffres et des underscores (
_). Ils ne peuvent pas commencer par un chiffre.Les colonnes doivent apparaître dans l’ordre exact spécifié (visitor_id suivi des attributs optionnels) pour que l’intégration fonctionne correctement.- Une fois que vous avez fourni les informations, cliquez sur Confirm pour créer la Data Ingestion Task.
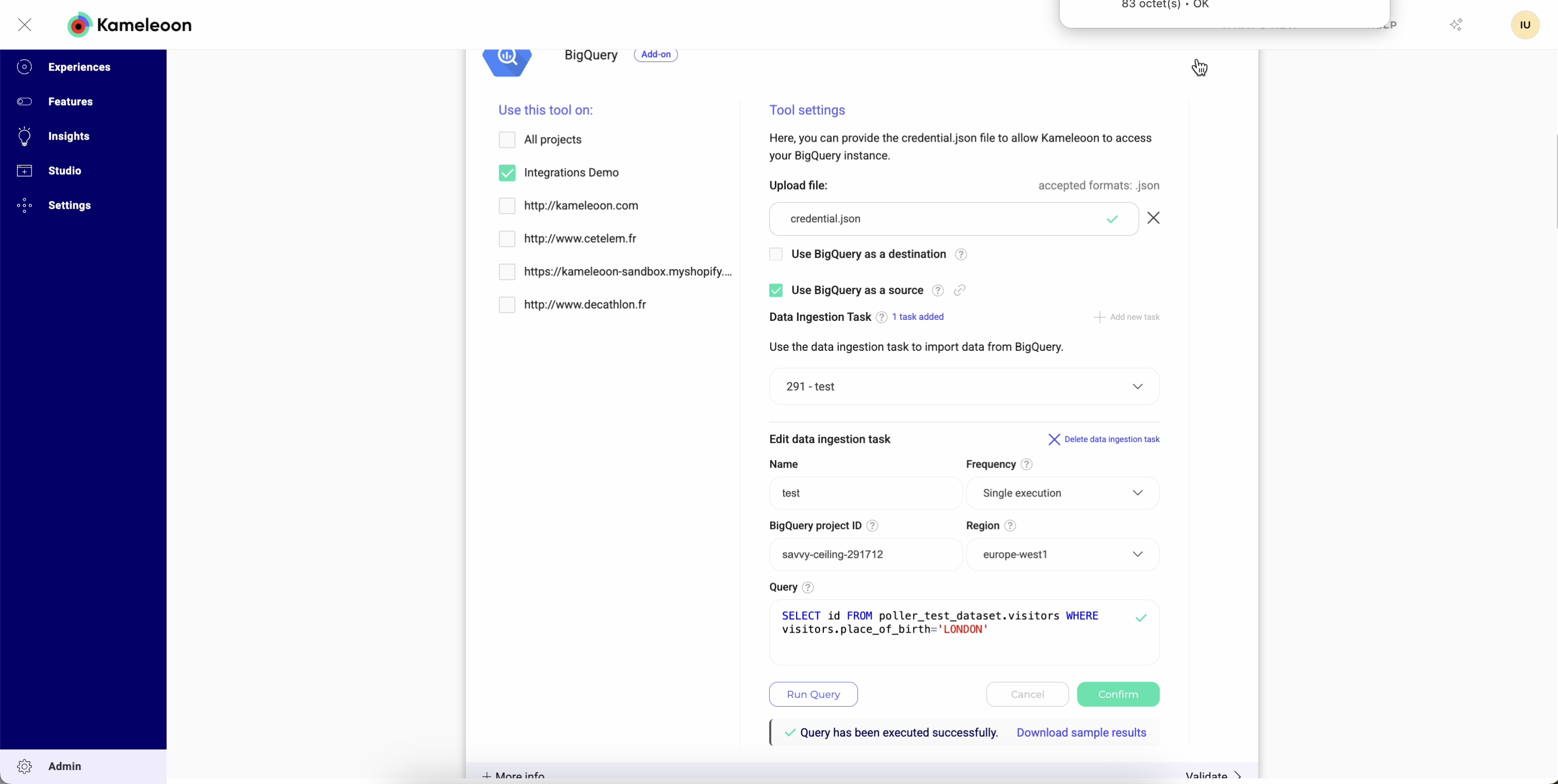
Exécuter votre requête avant l’ingestion
Avant d’enregistrer votre tâche d’ingestion, vous pouvez tester votre requête directement dans Kameleoon. Le test vous permet de :- Vérifier la connexion en temps réel.
- Confirmer que vos identifiants et droits d’accès sont corrects, ce qui aide à détecter les problèmes immédiatement, sans avoir à attendre le premier import de données.
- Valider la structure et l’accessibilité de vos données.
Mettre à jour une Data Ingestion Task
Pour mettre à jour une Data Ingestion Task :- Sélectionnez la tâche : Sélectionnez une Data Ingestion Task dans la liste déroulante.
- Modifiez les détails de la tâche : Modifiez les champs que vous souhaitez mettre à jour, tels que le nom de la tâche, la fréquence, l’ID de projet Amazon Redshift, la région ou la requête.
- Confirmez les modifications : Cliquez sur Confirm pour enregistrer les modifications apportées à la Data Ingestion Task.
Supprimer une Data Ingestion Task
Pour supprimer une Data Ingestion Task :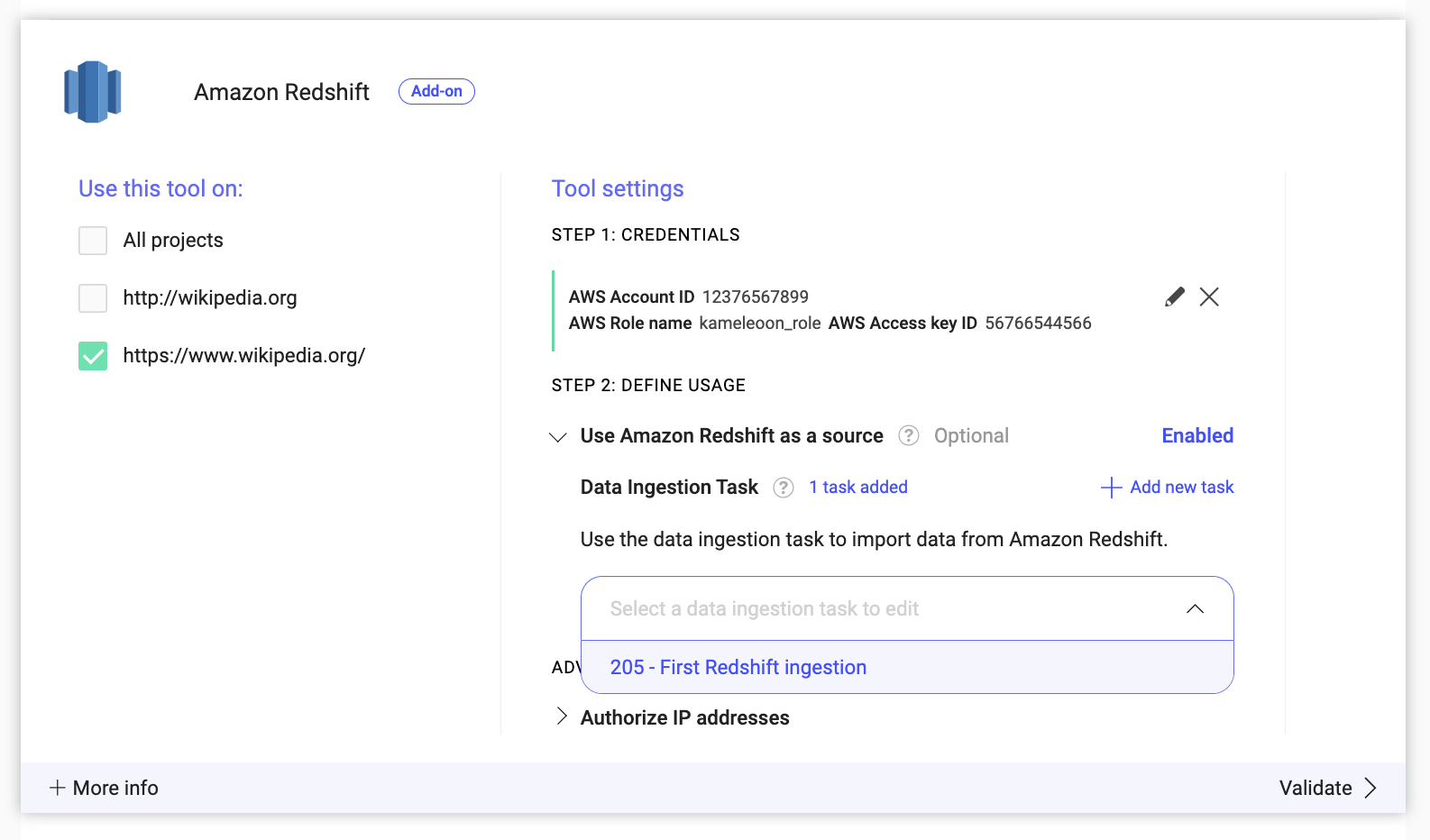
- Sélectionnez la tâche : Sélectionnez une Data Ingestion Task dans la liste déroulante.
- Lancez la suppression : Cliquez sur Delete ingestion task.
- Confirmez la suppression : Cliquez sur Confirm pour supprimer la Data Ingestion Task sélectionnée.