

- Permite una recopilación de datos precisa, mejorando la segmentación de audiencias para campañas personalizadas según las necesidades y preferencias específicas de la audiencia.
- Configure Data Ingestion Tasks para extraer datos de Redshift de forma eficiente.
Las integraciones con data warehouses están disponibles como complemento premium para nuestros módulos Web Experimentation y Feature Experimentation. Para obtener más información, póngase en contacto con su Customer Success Manager.
- Activar la funcionalidad: En la configuración del proyecto seleccionado, marque la casilla Use Amazon Redshift as a source.
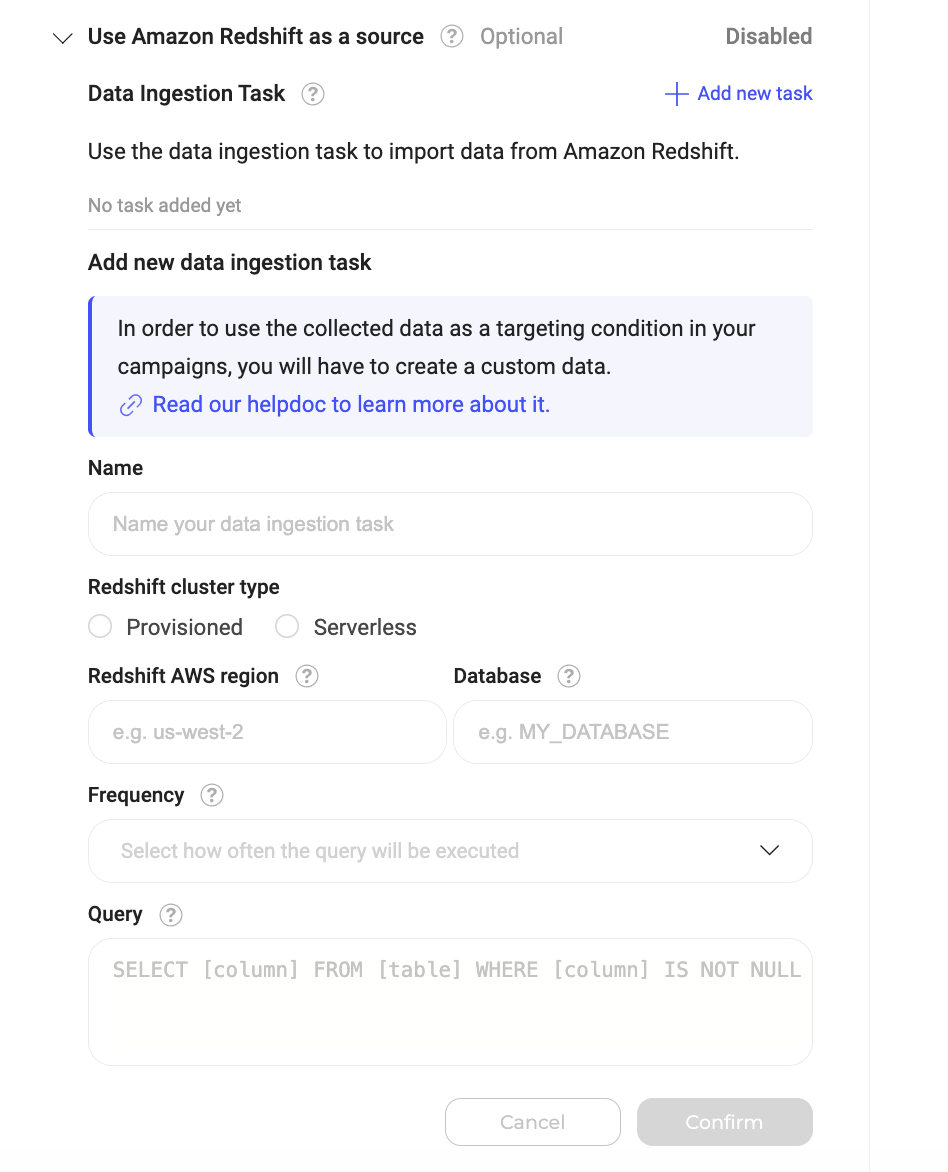
- Crear Data Ingestion Tasks: Con la funcionalidad activada, puede crear Data Ingestion Tasks. Estas tareas recuperan regularmente datos específicos de Amazon Redshift en función de las consultas SQL y las frecuencias que defina. Para crear una nueva Data Ingestion Task, haga clic en Add new task.
- Validar: Después de proporcionar la información requerida para la Data Ingestion Task, haga clic en Confirm para crear la tarea. Puede crear tareas adicionales repitiendo los pasos de nombrar la tarea, definir la consulta SQL y establecer la frecuencia. Una vez configuradas sus tareas, haga clic en Validate para guardar y aplicar la configuración.
- Crear un dato personalizado: Ahora que ha creado su Data Ingestion Task, nuestros servidores empezarán a recopilar datos en función de la frecuencia que configuró ejecutando la consulta en su instancia de Amazon Redshift. Para empezar a utilizar los datos recopilados, debe crear un dato personalizado.
- Crear un segmento: El último paso para segmentar a los usuarios en función de los datos recopilados es crear un segmento basado en su dato personalizado.
Data Ingestion Tasks
Las Data Ingestion Tasks son componentes esenciales de la integración con Amazon Redshift dentro de Kameleoon. Los datos recopilados por las Data Ingestion Tasks pueden utilizarse como condiciones de segmentación dentro de sus campañas de Kameleoon.Crear una Data Ingestion Task
Para crear una Data Ingestion Task:- Haga clic en Add new task.
- Complete el formulario:
- Name (Required): Dé a su tarea un nombre único y descriptivo para identificar su propósito.
- Redshift cluster type (Required): Especifique si su cluster de Redshift es provisioned o serverless. Si elige “provisioned”, se le pedirá que proporcione el identificador de su cluster. Si elige “serverless”, se le pedirá que proporcione el namespace y el workgroup de su cluster.
- Redshift AWS region (Required): El código de región de su cluster de Redshift. Puede encontrarlo en su consola de AWS. Ejemplo:
us-west-2. - Database (Required): Nombre de la base de datos de Redshift que contiene los datos que está ingiriendo.
- Frequency (Required): Especifique con qué frecuencia quiere que la tarea se ejecute y recupere datos de BigQuery (por ejemplo, por día).
- Query (Required): Proporcione la consulta SQL que recupera la audiencia de su base de datos de Amazon Redshift. La consulta debe seguir este formato específico:
SELECT visitor_id, attribute_1, .. attribute_N FROM your_events_table. - Campos
attribute_: Son opcionales y pueden utilizarse para escenarios de segmentación avanzados. Aprenda más sobre estos casos de uso avanzados aquí. visitor_id: Esta columna representa el identificador único de sus visitantes.
Los nombres de columna solo pueden contener letras, números y guiones bajos (
_). No pueden empezar por un número.Las columnas deben aparecer en el orden exacto especificado (visitor_id seguido de los atributos opcionales) para que la integración funcione correctamente.- Una vez que haya proporcionado la información, haga clic en Confirm para crear la Data Ingestion Task.
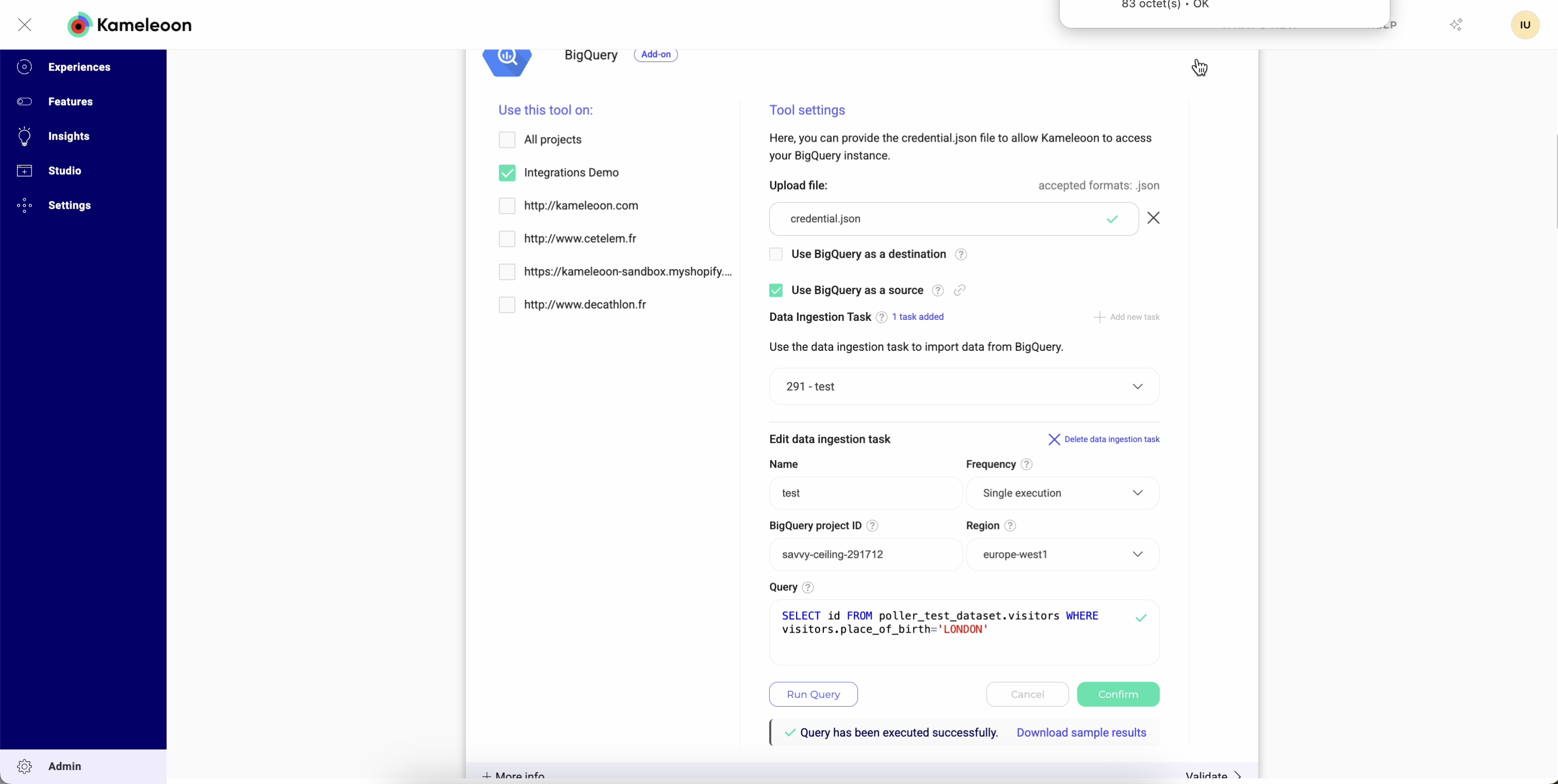
Ejecutar su consulta antes de la ingesta
Antes de guardar su ingestion task, puede probar su consulta directamente en Kameleoon. Las pruebas le permiten:- Verificar la conexión en tiempo real.
- Confirmar que sus credenciales y derechos de acceso son correctos, lo que ayuda a detectar problemas de inmediato, sin tener que esperar a la primera importación de datos.
- Validar la estructura y accesibilidad de sus datos.
Actualizar una Data Ingestion Task
Para actualizar una Data Ingestion Task:- Seleccionar la tarea: Seleccione una Data Ingestion Task en el menú desplegable.
- Editar los detalles de la tarea: Modifique los campos que desea actualizar, como el nombre de la tarea, la frecuencia, el ID de proyecto de Amazon Redshift, la región o la consulta.
- Confirmar cambios: Haga clic en Confirm para guardar los cambios en la Data Ingestion Task.
Eliminar una Data Ingestion Task
Para eliminar una Data Ingestion Task: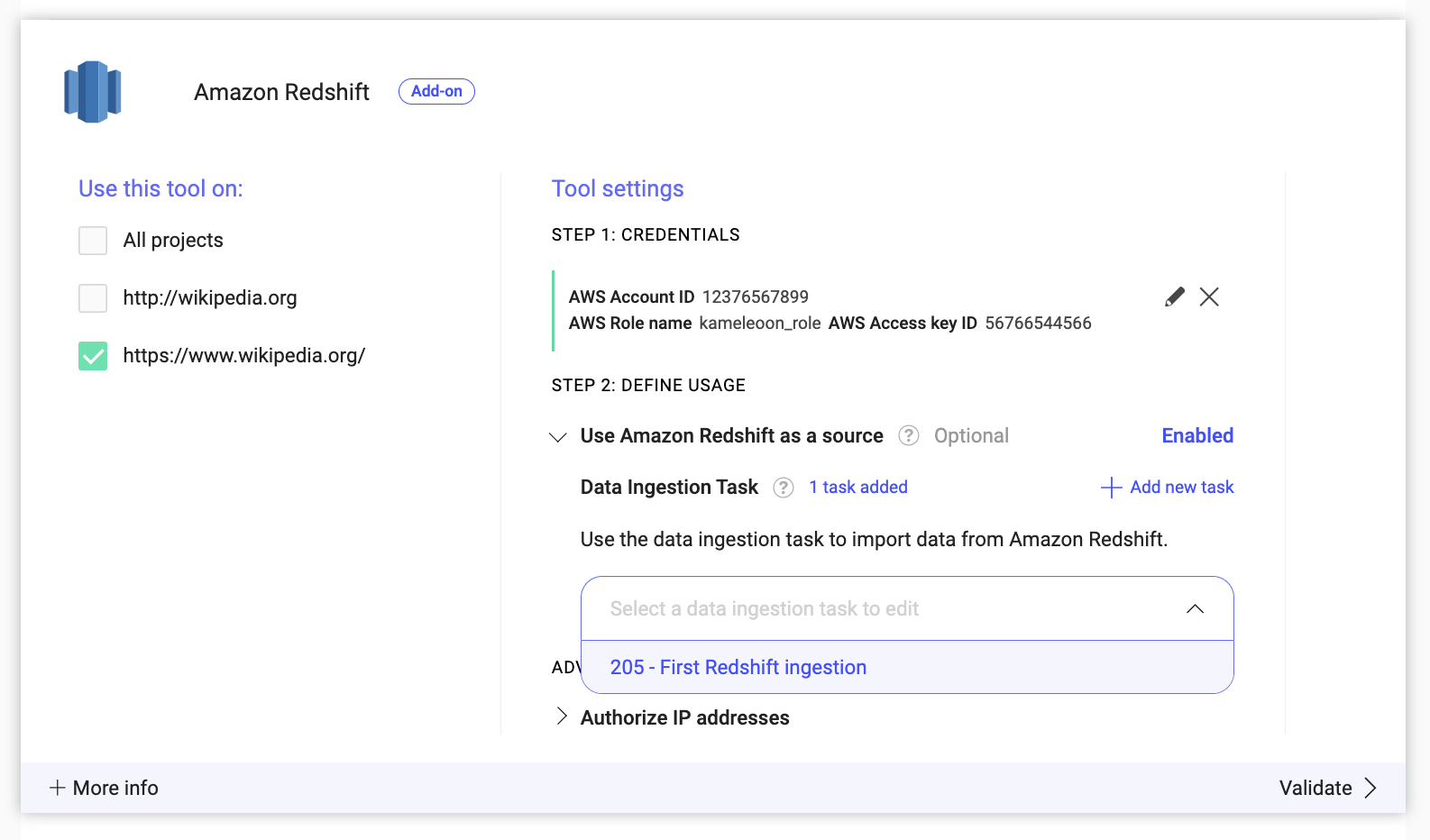
- Seleccionar la tarea: Seleccione una Data Ingestion Task en el menú desplegable.
- Iniciar la eliminación: Haga clic en Delete ingestion task.
- Confirmar la eliminación: Haga clic en Confirm para eliminar la Data Ingestion Task seleccionada.