


- Activar la funcionalidad: En la configuración del proyecto seleccionado, vaya a la sección denominada Use Databricks as a source para habilitar la funcionalidad.
- Crear Data Ingestion Tasks: Con la funcionalidad activada, ahora puede iniciar la creación de Data Ingestion Tasks. Estas tareas recuperan regularmente datos específicos de Databricks, en función de las consultas SQL y las frecuencias que defina. Para crear una nueva Data Ingestion Task, haga clic en Add new task.

- Validar: Después de proporcionar la información requerida para la Data Ingestion Task, haga clic en Confirm para crear la tarea. Puede crear tareas adicionales repitiendo los pasos de nombrar la tarea, definir la consulta SQL y establecer la frecuencia. Una vez configuradas sus tareas, haga clic en Validate para guardar y aplicar la configuración.
- Crear un dato personalizado: Ahora que ha creado su Data Ingestion Task, nuestros servidores empezarán a recopilar los datos en función de la frecuencia que configuró ejecutando la consulta en su instancia de Databricks. Para empezar a utilizar los datos recopilados, deberá crear un dato personalizado.
- Crear un segmento: El último paso para segmentar a los usuarios en función de los datos recopilados es crear un segmento basado en el dato personalizado que creó.
Data Ingestion Tasks
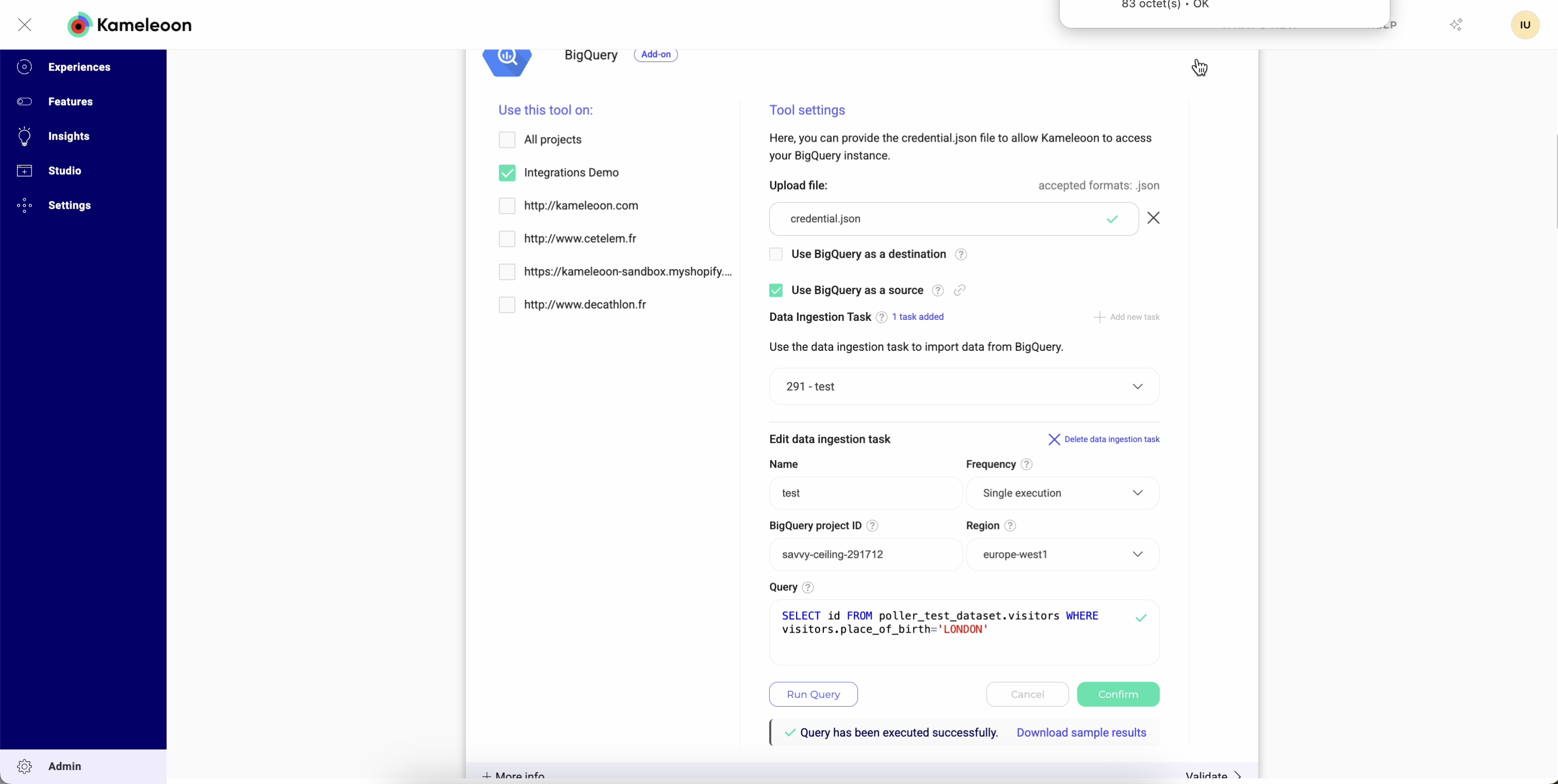
Las Data Ingestion Tasks son componentes esenciales de la integración con Databricks dentro de Kameleoon. Estas tareas le permiten recuperar regularmente datos específicos de Databricks, en función de consultas SQL y frecuencias predefinidas. Los datos recopilados a través de las Data Ingestion Tasks pueden utilizarse como condiciones de segmentación dentro de sus campañas de Kameleoon, lo que permite experiencias de usuario altamente personalizadas y basadas en datos.Crear una Data Ingestion Task
Para crear una Data Ingestion Task:
- Haga clic en Add new task.

- Complete el formulario:
- Name (Required): Dé a su tarea un nombre único y descriptivo para identificar su propósito.
- Frequency (Required): Especifique con qué frecuencia quiere que la tarea se ejecute y recupere datos de Databricks (por ejemplo, por día).
- Databricks Catalog (Required): Proporcione el nombre del “catalog” de Databricks que contiene los esquemas de los que desea que Kameleoon lea (la carpeta de nivel superior).
- Schema (Required): Proporcione el esquema que contiene las tablas que esta ingestion task consultará (por ejemplo,
user_data). - Query (Required): Proporcione la consulta SQL que recupera la audiencia de su base de datos de Databricks. La consulta debe seguir este formato específico:
SELECT visitor_id, attribute_1, .. attribute_N FROM your_events_table.
- Campos
attribute_: Son opcionales y pueden utilizarse para escenarios de segmentación avanzados. Aprenda más sobre estos casos de uso avanzados aquí. visitor_id: Esta columna representa el identificador único de sus visitantes.

Pautas
Nombres de columna
Los nombres de columna solo pueden contener letras (mayúsculas o minúsculas), números y guiones bajos (_). No pueden empezar por un número.
Orden de las columnas
Las columnas deben aparecer en el orden exacto especificado (visitor_id, seguido de los atributos opcionales) para que la integración funcione correctamente.
Una vez que haya proporcionado toda la información requerida, haga clic en Confirm para crear la Data Ingestion Task.
Ejecutar su consulta antes de la ingesta
Antes de guardar su ingestion task, puede probar su consulta directamente en Kameleoon. Las pruebas le permiten:- Verificar la conexión en tiempo real.
- Confirmar que sus credenciales y derechos de acceso son correctos, lo que ayuda a detectar problemas de inmediato, sin tener que esperar a la primera importación de datos.
- Validar la estructura y accesibilidad de sus datos.
Actualizar una Data Ingestion Task
Para actualizar una Data Ingestion Task:
- Seleccionar la tarea: Empiece seleccionando la Data Ingestion Task específica que desea editar en el menú desplegable.

- Editar los detalles de la tarea: Modifique los campos que desea actualizar, como el nombre de la tarea, la frecuencia, el Databricks Catalog, el Schema o la consulta.
- Confirmar cambios: Después de realizar las actualizaciones necesarias, haga clic en Confirm para guardar los cambios en la Data Ingestion Task.
Eliminar una Data Ingestion Task
Para eliminar una Data Ingestion Task:
- Seleccionar la tarea: Elija la Data Ingestion Task que desea eliminar en el menú desplegable.

- Iniciar la eliminación: Haga clic en el icono de eliminar situado en la parte superior derecha del formulario de edición.
- Confirmar la eliminación: Aparecerá un mensaje de confirmación. Haga clic en Confirm para eliminar la Data Ingestion Task seleccionada.