

- Ermöglicht eine präzise Datenerfassung und verbessert das Audience-Targeting für Kampagnen, die auf die spezifischen Bedürfnisse und Präferenzen der Zielgruppe zugeschnitten sind.
- Konfigurieren Sie Data Ingestion Tasks, um Daten effizient aus Redshift zu extrahieren.
Data-Warehouse-Integrationen sind als Premium-Add-on für unsere Module Web Experimentation und Feature Experimentation verfügbar. Für weitere Informationen wenden Sie sich bitte an Ihren Customer Success Manager.
- Funktion aktivieren: Aktivieren Sie in der Konfiguration des ausgewählten Projekts das Kontrollkästchen Use Amazon Redshift as a source.
- Data Ingestion Tasks erstellen: Mit aktivierter Funktion können Sie Data Ingestion Tasks erstellen. Diese Aufgaben rufen regelmäßig bestimmte Daten aus Amazon Redshift auf der Grundlage Ihrer definierten SQL-Abfragen und Häufigkeiten ab. Um eine neue Data Ingestion Task zu erstellen, klicken Sie auf Add new task.
- Validieren: Nachdem Sie die erforderlichen Informationen für die Data Ingestion Task angegeben haben, klicken Sie auf Confirm, um die Aufgabe zu erstellen. Sie können zusätzliche Aufgaben erstellen, indem Sie die Schritte zum Benennen der Aufgabe, Definieren der SQL-Abfrage und Festlegen der Häufigkeit wiederholen. Sobald Sie Ihre Aufgaben konfiguriert haben, klicken Sie auf Validate, um Ihre Konfigurationseinstellungen zu speichern und anzuwenden.
- Eine Custom Data erstellen: Nachdem Sie Ihre Data Ingestion Task erstellt haben, beginnen unsere Server mit der Datensammlung basierend auf der von Ihnen konfigurierten Häufigkeit, indem sie die Abfrage auf Ihrer Amazon Redshift-Instanz ausführen. Um die gesammelten Daten zu verwenden, müssen Sie eine Custom Data erstellen.
- Ein Segment erstellen: Der letzte Schritt zum Targetieren von Benutzern auf der Grundlage der gesammelten Daten besteht darin, ein Segment auf der Grundlage Ihrer Custom Data zu erstellen.
Data Ingestion Tasks
Data Ingestion Tasks sind wesentliche Komponenten der Amazon Redshift-Integration in Kameleoon. Die durch Data Ingestion Tasks gesammelten Daten können als Targeting-Bedingungen in Ihren Kameleoon-Kampagnen verwendet werden.Eine Data Ingestion Task erstellen
So erstellen Sie eine Data Ingestion Task:- Klicken Sie auf Add new task.
- Füllen Sie das Formular aus:
- Name (Required): Geben Sie Ihrer Aufgabe einen eindeutigen und beschreibenden Namen, um ihren Zweck zu identifizieren.
- Redshift cluster type (Required): Geben Sie an, ob Ihr Redshift-Cluster provisioned oder serverless ist. Wenn Sie „provisioned” wählen, werden Sie aufgefordert, Ihre Cluster-ID anzugeben. Wenn Sie „serverless” wählen, werden Sie aufgefordert, den Namespace und das Workgroup Ihres Clusters anzugeben.
- Redshift AWS region (Required): Der Regionscode Ihres Redshift-Clusters. Sie finden ihn in Ihrer AWS-Konsole. Beispiel:
us-west-2. - Database (Required): Name der Redshift-Datenbank, die die von Ihnen aufgenommenen Daten enthält.
- Frequency (Required): Geben Sie an, wie oft die Aufgabe ausgeführt werden und Daten aus BigQuery abrufen soll (zum Beispiel pro Tag).
- Query (Required): Geben Sie die SQL-Abfrage an, die die Zielgruppe aus Ihrer Amazon Redshift-Datenbank abruft. Die Abfrage muss diesem spezifischen Format folgen:
SELECT visitor_id, attribute_1, .. attribute_N FROM your_events_table. attribute_-Felder: Diese sind optional und können für erweiterte Targeting-Szenarien verwendet werden. Weitere Informationen zu diesen erweiterten Anwendungsfällen finden Sie hier.visitor_id: Diese Spalte stellt die eindeutige Kennung Ihrer Besucher dar.
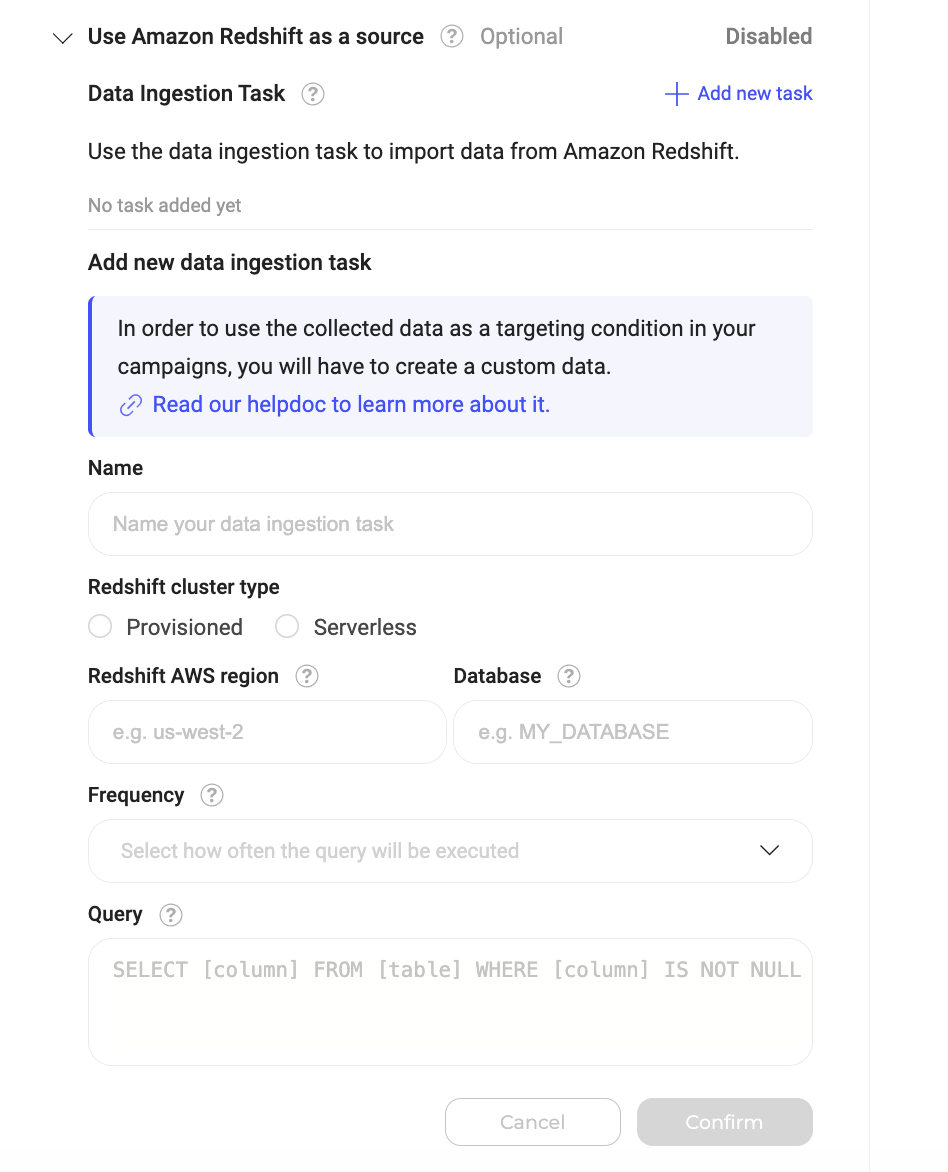
Spaltennamen dürfen nur Buchstaben, Zahlen und Unterstriche (
_) enthalten. Sie dürfen nicht mit einer Zahl beginnen.Spalten müssen in der genau angegebenen Reihenfolge erscheinen (visitor_id gefolgt von optionalen Attributen), damit die Integration korrekt funktioniert.- Sobald Sie die Informationen angegeben haben, klicken Sie auf Confirm, um die Data Ingestion Task zu erstellen.
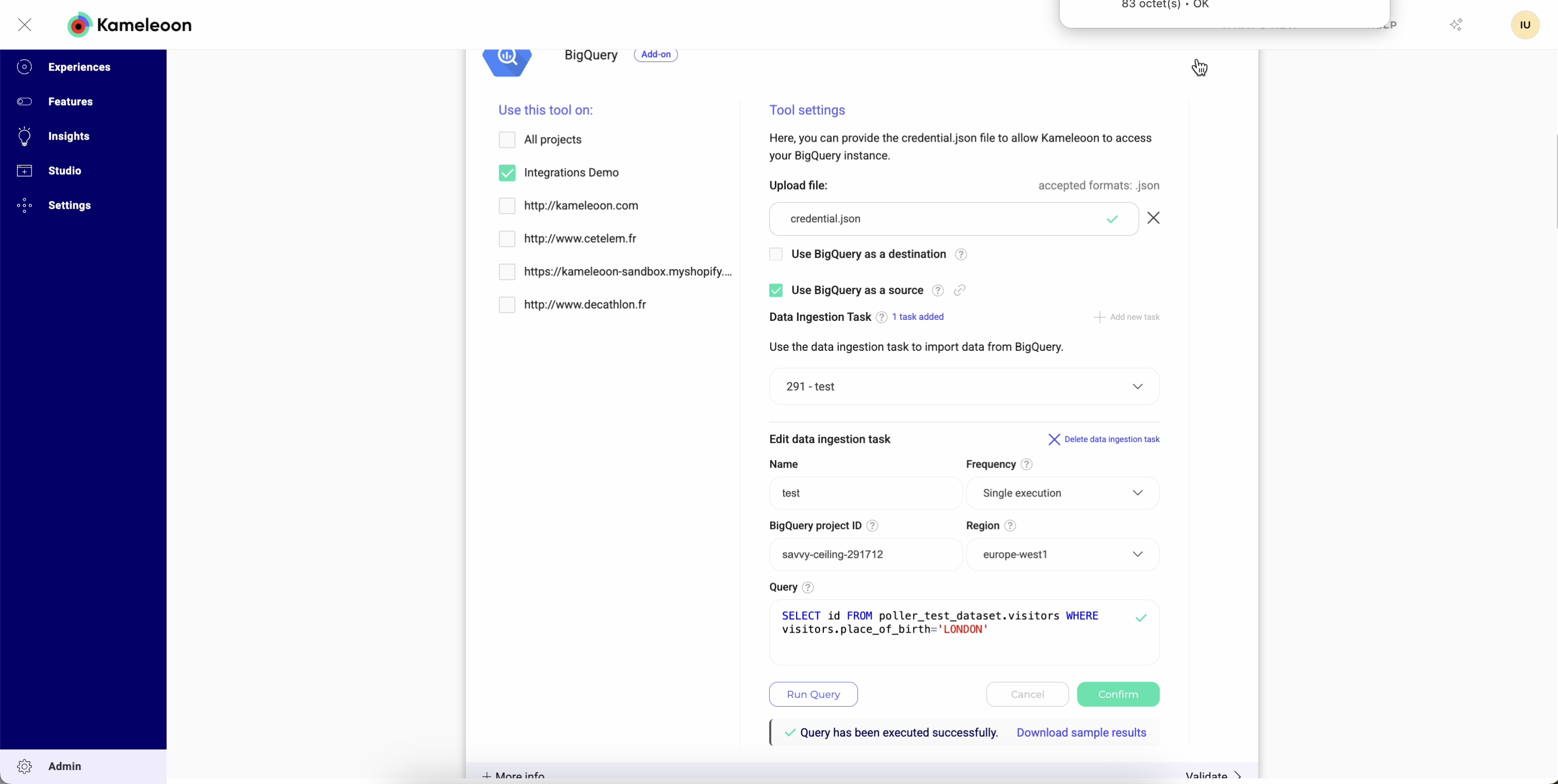
Führen Sie Ihre Abfrage vor der Ingestion aus
Bevor Sie Ihre Ingestion Task speichern, können Sie Ihre Abfrage direkt in Kameleoon testen. Mit dem Testen können Sie:- Die Verbindung in Echtzeit überprüfen.
- Bestätigen, dass Ihre Anmeldedaten und Zugriffsrechte korrekt sind, was hilft, Probleme sofort zu erkennen, ohne auf den ersten Datenimport warten zu müssen.
- Die Struktur und Zugänglichkeit Ihrer Daten validieren.
Eine Data Ingestion Task aktualisieren
So aktualisieren Sie eine Data Ingestion Task:- Aufgabe auswählen: Wählen Sie eine Data Ingestion Task aus dem Dropdown-Menü aus.
- Aufgabendetails bearbeiten: Ändern Sie die Felder, die Sie aktualisieren möchten, z. B. den Namen der Aufgabe, die Häufigkeit, die Amazon Redshift-Projekt-ID, die Region oder die Abfrage.
- Änderungen bestätigen: Klicken Sie auf Confirm, um die Änderungen an der Data Ingestion Task zu speichern.
Eine Data Ingestion Task löschen
So löschen Sie eine Data Ingestion Task: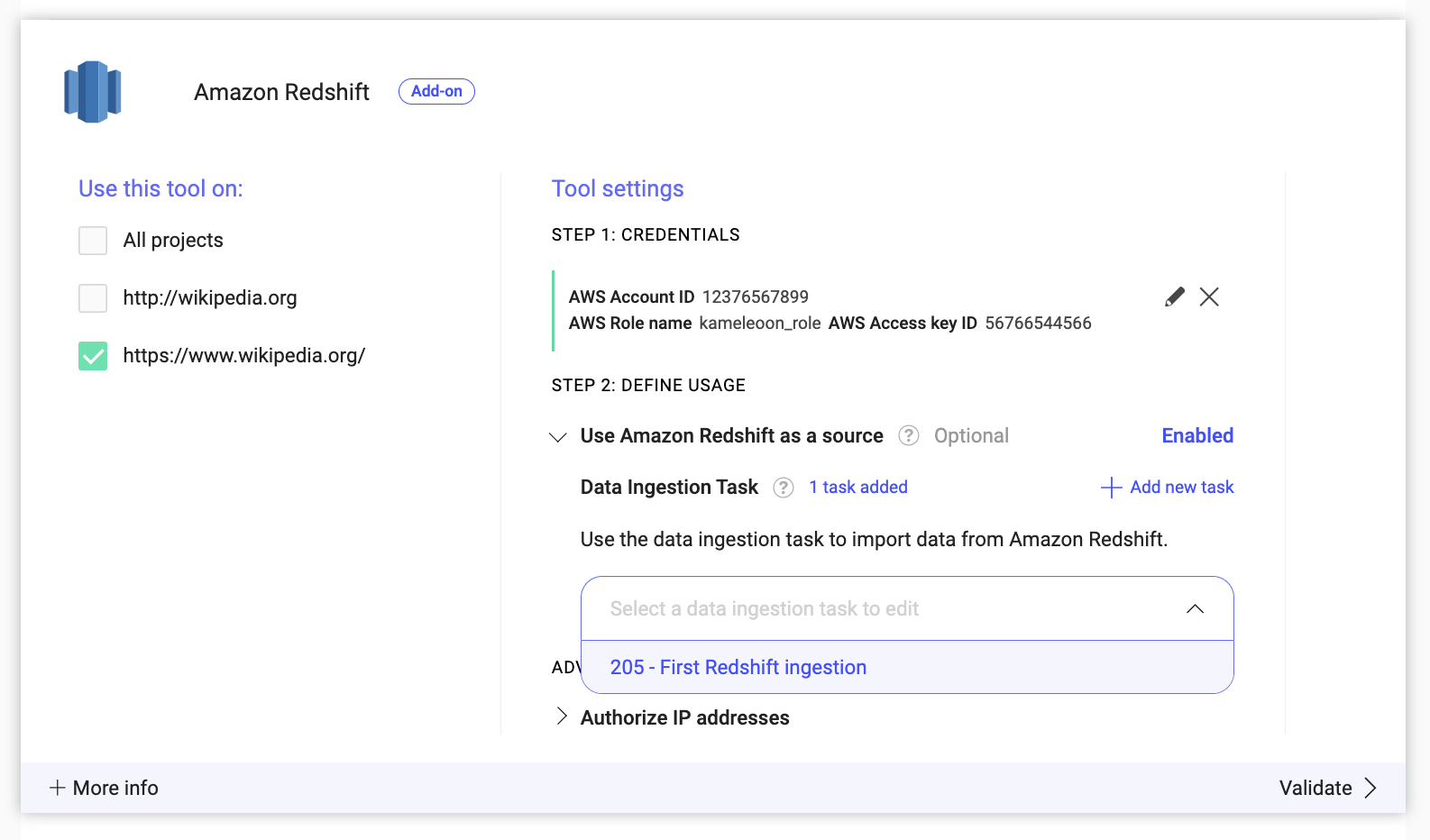
- Aufgabe auswählen: Wählen Sie eine Data Ingestion Task aus dem Dropdown-Menü aus.
- Löschung starten: Klicken Sie auf Delete ingestion task.
- Löschung bestätigen: Klicken Sie auf Confirm, um die ausgewählte Data Ingestion Task zu löschen.